Share this article



I’ve seen this mistake a few times, and it resulted in skyrocketing costs. So, let’s break down how to avoid this error.
DynamoDB is a NoSQL, non-relational, key-value database. This means that if you want to retrieve a value (a record/item in the database), you need to know the key. For example, imagine the following Users table:
| Field | Data Type | Description |
|---|---|---|
| username | String | Partition Key – A unique identifier for each user |
| String | User’s email | |
| status | String | Account status (e.g., "active", "pending", or "inactive") |
If you know the username, you can query the Users table and get the email and status for that username. This is similar to the SQL query: SELECT * FROM Users WHERE username = ‘jane_doe’; (Note: this is just an example, as DynamoDB is NoSQL, and SQL queries aren’t used in DynamoDB).
Now, imagine that in some situations, you don’t have the user’s username, only their email. You won’t find a similar query in DynamoDB like WHERE email=’jane.doe@example.com’, because email isn’t the key. To retrieve the value, you need the key, as this is a key-value database.
There are two ways:
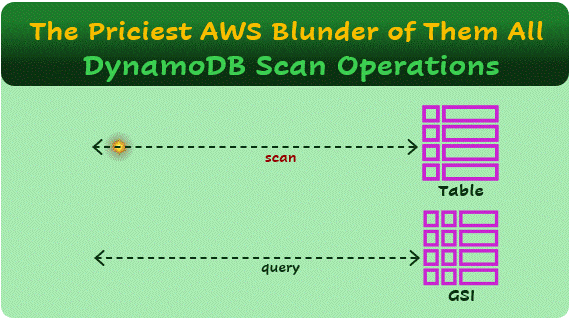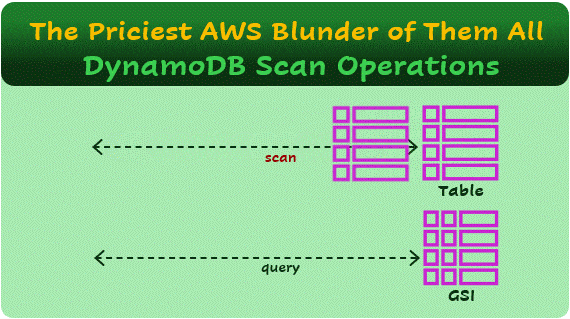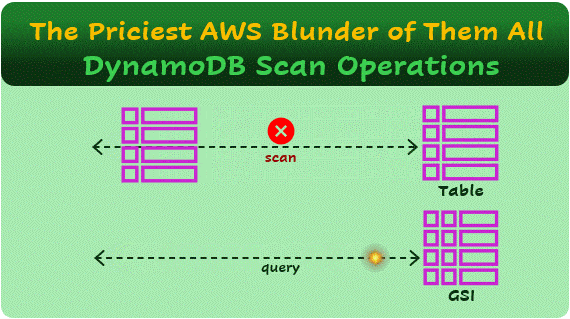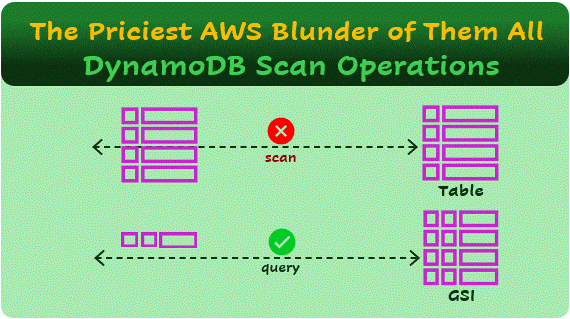
A scan operation is a mistake when performed repeatedly on a table with many records. On a small table, or with a few scan executions per day, it may not necessarily be an error.
You can think of a scan operation in two stages: First, the query SELECT * FROM Users, which returns all records in the table. You’ll pay for reading all the table data, based on the Read Capacity Units (RCUs) model.
After that, DynamoDB applies the filter WHERE email=’jane.doe@example.com’, finalizing the scan operation.
Let’s run a hypothetical calculation. Imagine there are 500,000 users in the Users table, and each record averages 80 bytes. You would pay for 80 bytes x 500,000 records = 40MB returned, which would result in 10,000 RCUs per query for a strongly consistent read. Now imagine that this query runs a million times a month. This would total 10 billion RCUs per month. For On-Demand capacity in the Virginia region, the company would pay $2,500/month for these queries alone.
A Global Secondary Index (GSI) in DynamoDB is an additional index that allows quick lookups using a field that is not the partition key of the table. However, GSIs consume additional storage and incur extra costs since they essentially store a copy of the indexed attributes, now with a new key.
Since we need many queries by email (which is not the key), let’s create a GSI with email as the key. Now, let’s calculate the costs.
First, let’s calculate the additional storage cost for the GSI: 80 bytes x 500,000 records = 40MB, which totals 1 cent per month in the Virginia region.
Now, let’s calculate the RCUs consumed in a month. In the GSI query, you have the key, which is now email, so you can perform a query like Select * from GSI_Users WHERE email = ‘jane.doe@example.com’. This query will return the record, averaging 80 bytes, which totals 1 RCU per query. For 1 million queries per month, that’s 1 million RCUs, costing just 25 cents per month.
So, using GSI, the cost is: $Storage_GSI + $RCUs_GSI = $0.25/month + $0.01/month = $0.26/month.
Comparing costs:
Of course, this 10,000x difference in the final cost is for hypothetical numbers. So, you may be asking: A) Does this cost mistake actually happen? B) If it does, why don’t people catch it immediately?
Yes, it does. Among DynamoDB experts, it doesn’t happen. However, many developers using DynamoDB for the first time don’t study its key concepts, such as partition key, scan, GSI, etc. They use abstraction tools like Object-Relational Mapping (ORM) tools that execute scan operations “under the hood.” I’ve seen this error occur frequently with the Spring Data DynamoDB module, along with the @EnableScan annotation.
DynamoDB isn’t relational, so relational mapping techniques aren’t ideal. DynamoDB’s purpose isn’t to abstract usage for developers. It’s quite the opposite – you should know your queries and the indexes you’ve created, allowing you to pay only $0.26 for a million queries. If developers don’t have time to learn the key concepts of DynamoDB (which takes about an hour), they’d be better off using a relational database to avoid paying $2,500 for a million identical query executions.
When this error happens, it can take time to detect. First, development environments have fewer accesses, resulting in fewer scan occurrences. Additionally, their tables contain fewer records, making a scan operation much less costly. Typically, costs in development environments are negligible when scan operations occur. This is why the mistake often isn’t caught before hitting production.
In production, tables usually start small and grow over time, making it hard to detect at first. Even when monitoring costs, it can still go unnoticed, as DynamoDB’s table-level costs aren’t visible on AWS linked accounts. This is typical for large companies with linked accounts in AWS Organizations.
Once deployed, this error may remain masked for hours or even months, depending on access volume, table growth, and how diligently costs are monitored.
In many cases, detecting scan operations became more difficult after AWS introduced the On-Demand capacity mode for DynamoDB in November 2018. Previously, scan operations would hit throttling limits faster, making it easier to identify hidden scans. With On-Demand mode, throttling is less apparent, making scans more costly and harder to detect (Throttling comparison: On-Demand vs. Provisioned).
It’s also worth noting that the On-Demand mode is typically more expensive than Provisioned, especially for workloads with predictable demand, where Provisioned is usually the better choice.
As a Developer: Learn the concepts of partition key, scan, and GSI, at the very least. For queries without a partition key using GSI, I created this example code on GitHub: https://github.com/LevyVianna/bootcamp-apis-dynamoDB/blob/main/src/main/java/bootcamp/user_crud_api/repository/UserRepository.javahttps://github.com/LevyVianna/bootcamp-apis-dynamoDB
As an Ops/SRE team member:
Check if scan operations are being executed on any table via CloudWatch metrics. Filter by scan operations, and you’ll be able to see all the scans being performed.
Also, in AWS Cost Explorer, compare the RCU costs with WCU costs. If RCU expenses are rising disproportionately, this is a good indication that scan operations are occurring in some of your DynamoDB tables. Filter by DynamoDB in Cost Explorer and select usageType in the dimensions for better visibility.
As a Cloud Governance/Security team member:
You can block scan operations using IAM roles. For example, you should add this policy, in all non-production environments, to the role of your applications running in Lambda, ECS, Fargate, or EC2 to restrict scan operations while allowing other actions:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1725992424040",
"Action": [
"dynamodb:Scan"
],
"Effect": "Deny",
"Resource": "arn:aws:dynamodb:us-east-1:55555555:table/table_name"
},
{
"Sid": "Stmt1725992460139",
"Action": "dynamodb:*",
"Effect": "Allow",
"Resource": "arn:aws:dynamodb:us-east-1:55555555:table/table_name"
}
]
}
Replace “55555555” with your AWS account and “table_name” with your DynamoDB table name.
Thus, when the developer deploys the application from the local environment to a development environment, the application may receive a “deny” for the scan operation, even in a non-production setting. This way, the developer will have time to understand the issue, create the necessary GSI, and modify the application to perform queries correctly.
Amazon DynamoDB is a fantastic database and may be a perfect fit for your workload. But it’s crucial to avoid “the priciest AWS blunder of them all”: unplanned scan operations.

Levy Vianna
September 25, 2024
© 2024 All Rights Reserved | Privacy Policy | Terms of Use

